Magnetic Starter is mainly applied to circuit of AC 50 or 60Hz,voltage up to 550V for far distance making and breaking circuit and frequent start and control motor. It has the features of small volume, light, weight, low power consumption, high efficiency, safe and reliable perfomance etc.
The types of Magnetic Starters are as following:
LC1-D Magnetic Starter
Magnetic Starter,Magnetic Motor Starter,3 Phase Motor Starter,3 Phase Magnetic Starter Ningbo Bond Industrial Electric Co., Ltd. , https://www.bondelectro.com
NEW Type Magnetic Starter
BLS-MB Magnetic Starter
Star-Delta Starter

Common algorithm for machine learning feature selection
**Summary**
**(1) What is Feature Selection?**
Feature Selection, also known as Feature Subset Selection (FSS) or Attribute Selection, refers to the process of selecting a subset of relevant features from a larger set to build a more effective and efficient model. This technique helps in reducing complexity and improving model performance by focusing only on the most important attributes.
**(2) Why Perform Feature Selection?**
In real-world machine learning applications, datasets often contain a large number of features, many of which may be irrelevant or redundant. Additionally, some features might be highly correlated, leading to issues such as overfitting or increased computational cost. The main reasons for performing feature selection include:
- Reducing the time required for feature analysis and model training.
- Avoiding the "curse of dimensionality," which can degrade model performance and increase complexity.
- Improving model accuracy by removing noise and redundancy.
- Enhancing model interpretability, making it easier for researchers to understand the underlying data patterns.
By selecting only the most relevant features, we not only improve model efficiency but also gain better insights into the data generation process.

**2. Feature Selection Process**
**2.1 General Process of Feature Selection**
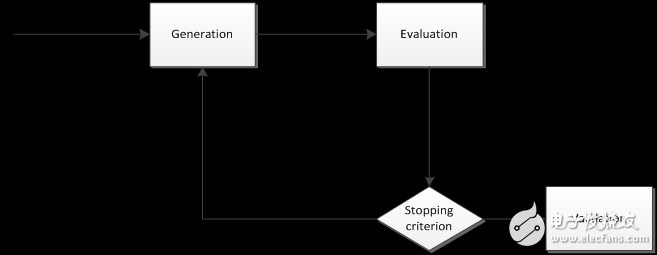
The general process of feature selection is illustrated in Figure 1. It typically involves generating a feature subset from the original set, evaluating its quality using an evaluation function, comparing the result with a stopping criterion, and continuing the search until the best subset is found. Once selected, the feature subset is usually validated on a separate dataset to ensure its effectiveness.
In summary, the feature selection process generally includes four key components:
1. **Generation Procedure**: Searching for potential feature subsets.
2. **Evaluation Function**: Assessing the quality of each subset.
3. **Stopping Criterion**: Determining when to terminate the search.
4. **Validation Procedure**: Verifying the selected subset on a validation dataset.
**Figure 1. Process of Feature Selection (M. Dash and H. Liu 1997)**
**2.2 Generation Process**
The generation process refers to the method used to explore the space of possible feature subsets. Search algorithms are typically categorized into three types: Complete Search, Heuristic Search, and Random Search, as shown in Figure 2.
**Figure 2. Generation Process Algorithm Classification (M. Dash and H. Liu 1997)**
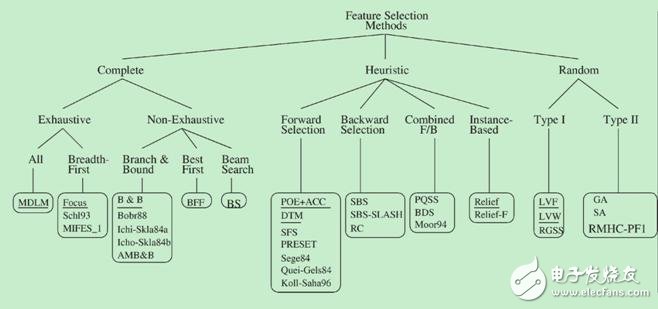
**2.2.1 Complete Search**
Complete search methods aim to explore all possible feature subsets. They are further divided into two types:
**(1) Breadth-First Search**
This algorithm explores all possible feature combinations level by level. It is exhaustive and has a time complexity of O(2^n), making it computationally expensive for large datasets.
**(2) Branch and Bound Search**
This method improves upon exhaustive search by pruning branches that cannot yield better results than the current best solution. It reduces the search space while still guaranteeing optimality.
**(3) Beam Search**
This approach starts by selecting the top N features and then expands them iteratively. A priority queue is used to keep track of the most promising subsets, ensuring a balance between exploration and efficiency.
**(4) Best-First Search**
Similar to beam search, this method uses a priority queue to select the most promising subsets. However, unlike beam search, it does not limit the size of the queue, allowing for more extensive exploration.
These search strategies form the foundation of many feature selection techniques, enabling practitioners to efficiently navigate high-dimensional data spaces.