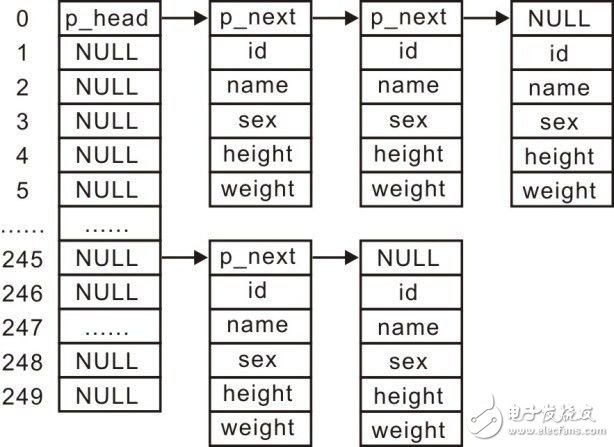
Recently, Professor Zhou Ligong has published his painstaking work "Programming and Data Structure" for several years. The electronic version has been distributed to electronic engineers and college groups for free download. Authorized by Professor Zhou Ligong, the content of this book is serialized. > > >> 1.1 Hash Table > > > 1.1.1 Question Suppose you need to design an information management system to manage the information about 10,000 students. You can find the information of the corresponding students through the student number. Each student record contains information such as student number, name, gender, height, and weight. which is: Typedef struct _student{ Unsigned char id[6]; // student number (6 bytes) Char name[10]; // name Char sex; // sex Float height, weight; // height, weight As an information management system, you must first be able to store student records. How do you store these tens of thousands of records? Simply, you can use a contiguous memory to store student records, for example, using a large array of storage, each array element can store a student record: Student_t student_db[10000]; When using an array to store student information, how do you find the corresponding information by the student number? If the student numbering is a very ideal situation, the student numbers of 10,000 students are arranged in the order of 0 ~ 9999. You can directly find the corresponding array elements by using the student number as the index value of the array. The storage and searching efficiency is very high. high. But in fact, the student number is often not so simple, a common arrangement method is "grade + professional code + class + class number", for example, 6-byte student number is 0x20, 0x16, 0x44, 0x70, 0x02, 0x39 That is, it means that in 2016, the professional code is 4470 (that is, computer major), and class 2 is class 39. At this point, the method of finding student information through the student number is also very simple. Starting directly from the first student record, the student records are sequentially traversed, and the student number in the record is compared with the student number of the student who is looking for the student number. Information about the student is found, as detailed in Listing 3.61 . Listing 3.61   Sequential lookup sample program 1 student_t * student_search(unsigned char id[6]) 2 { 3 for (int i = 0; i < 10000; i++) { 4 if (memcmp(student_db[i].id, id, 6) == 0) { // Compare 5 return &student_db[i]; // Found the student's information 6 } 7 } 8 return NULL; // The student's information was not found Obviously, if the sequential search method is used, the more student records, the more times you need to compare when searching, and the lower the efficiency. When the number of records recorded by students is tens of thousands, it may take tens of thousands of times to find the corresponding student information. How to achieve a search with higher efficiency? Ideally, if you store the student number as an array index, the lookup is very efficient. In this case, if you increase the array capacity to the maximum value of the student number plus 1 (to include the student number 0), you can directly use the student number as the index value of the array. Since the student number is composed of 6 bytes, the array must be able to hold 2 48 records. How much storage space does it take? Even if a record occupies only one byte, it needs 262144 G storage space, not to mention the computer hard drive is not so big! If only 10,000 of these records are used, the remaining (2 48 - 10000 ) space will be extremely wasteful, which is obviously not desirable. In the search algorithm, the very classic and efficient algorithm is “dichotomy searchâ€, which is calculated by 10000 records, and only needs to be compared 14 times (log210000). However, the premise of using "dichotomy search" is that the information must be arranged in an orderly manner, that is, the student records must be stored in the order of the student numbers, which results in a large amount of movement operations of the information stored in the database when adding or deleting student information. For example, the array has stored 9999 records in the order of the student number from small to large, and now writes the 10000th record. If the record has the smallest student number, it needs to be written to the front of all records, which needs to be stored before. The 9999 records are all moved backwards to reserve the space of the first element, and then the new student record is written into the space corresponding to the first element. It can be seen that although this method can improve the efficiency of searching, it sacrifices the efficiency when adding information. In order to add a lot of data movement when adding information, can you change the storage method? For example, using a "single-link list" structure in which the storage space is not continuous, the individual student records are "chained". The schematic diagram is shown in Figure 3.23 . Figure 3.23 Using a singly linked list to manage student records When using a linked list to manage student records, an orderly alignment is required to find the correct insertion position each time a new node is inserted, without the need to move large amounts of data. Since the storage space is not continuous, it is impossible to use the "dichotomy" to find the student information, and the orderly arrangement does not solve the problem of inefficient search. Whether or not it is ordered, the search needs to be searched from the beginning. Thus, the use of "difference search" must sacrifice the efficiency of record writing to achieve an orderly arrangement of all records, making the efficiency of writing records very low. Although the underlying "sequential lookup" has no effect on the efficiency of writing records, the search efficiency is extremely low. Therefore, both of these situations are too extreme, either choosing very low write efficiency or choosing very low search efficiency. Why not combine the two to compromise the efficiency of the write and the efficiency of the search? For example, the record "two points" into two parts, using two arrays to store: Student_t student_db0[5000]; Student_t student_db1[5000]; Assume a predetermined, when the learning value smaller than a certain number (i.e. 201,044,700,239), the record is stored in student_db0, on the contrary, the record is stored in student_db1. As a result, when writing a record, only one more judgment statement is needed, which does not affect the performance. In the search, as long as the student number is judged in which array, it can be searched in order. At this point, the number of times the search needs to be compared has been reduced from the maximum of 10,000 to 5,000. It can be seen that the storage efficiency can be significantly improved by storing the information in two arrays in a simple way. In order to continue to improve the efficiency of the search, you can continue to group, for example, into 250 groups, each group has a size of 40: Student_t student_db0[40]; Student_t student_db1[40]; ...... Student_t student_db248[40]; Student_t student_db249[40]; Obviously, using this definition is too cumbersome. Since the size of each array is the same, you can directly define an array of 40 student records as a type: Typedef student_t student_group_t[40]; Student_group_t student_db[250]; At this time, each packet has a size of 40, so that it is only necessary to compare up to 40 times when searching for records. Next, you need to define a grouping rule to find out which group the record belongs to by the student number. When defining rules, all records should be distributed evenly among groups as much as possible. There should not be some records in which some groups are stored, and some groups store very few records. But this is not an easy task and requires an accurate analysis of the data distribution of the student number. If it is divided into 250 groups, assuming that the student numbers are evenly distributed, the remainder of the 6-byte school number is divided by 250 (the number of packets) (the remainder method) can be used as the index of the packet, due to writing and searching. It is necessary to find out which group the record should belong to by the student number. Therefore, according to the basis of the student number grouping, a function for finding the corresponding group index by the student number can be written. See Listing 3.62 for details . Listing 3.62   Sample program by student number 1 int db_id_to_idx(unsigned char id[6]) 2 { 3 int i, sum = 0; 4 5 for (i = 0; i < 6; i++) { 6 sum += id[0]; 7 } 8 return sum % 250; The number of groups is regarded as 250 as a table of size 250. Each table can store an array of 40 student records. The db_id_to_idx() function is used to find the position of the keyword ID in the table. Among them, the table with size 250 is the “hash tableâ€, as shown in Figure 3.24 . The db_id_to_idx() function is a "hash function", and the result of the hash function (packet index) is called a "hash value". Figure 3.24 Hash The core work of the hash table is the selection of the hash function. The searched keyword is sent to the hash function to generate a hash value. The choice of the hash function directly determines the distribution of the record. It is necessary to ensure that all records are evenly distributed. Distributed in each group. In the above example, an array of the same size is defined in each group as the space for record storage. This is optimal if, according to the grouping rules, it is ensured that it is evenly distributed among the individual packets. In fact, student records will change, and may be added or deleted. It is difficult to guarantee 100% complete averaging according to the currently defined grouping rules. If each group uses an array of the same size as the storage space of the record, it may cause some of the arrays to be unfilled, and some of the arrays may not be saved, resulting in some student records having nowhere to exist, resulting in serious data management. problem. Since arrays are defined in advance, the dynamic performance is poor, and the dynamic performance of the linked list is better. You can add and delete nodes as needed, and change the length of the linked list. Therefore, you can use the linked list to manage student records, even if the distribution is uneven, only There is a difference in the length of the linked list, and there is no problem that the data cannot be stored. The schematic diagram is shown in Figure 3.25 . Figure 3.25 Chained Hash Table When a student record is managed using a linked list, the actual content of each entry of the hash table is the header of the linked list. The type of the list header node slist_head_t (slist.h) is defined as follows: Typedef struct _slist_node{ Struct _slist_node *p_next; // pointer to the next node }slist_node_t; Based on this, a list header of the slist_head_t type can be stored in each entry of the hash table. The definition of the hash table is as follows: Typedef slist_head_t student_group_t; Student_group_t student_db[250]; According to the analysis of the chain structure of the hash table, write a hash table based chain of information management systems, provided only as examples to add, delete, find three functions. Of course, before using these features, you must also define a type of hash table object, in order to use the type to define a specific hash table instance, and then use the various functional interfaces to operate the instance. > > >> 1.1.2 Types of hash tables The hash table type struct _hash_db is defined as follows: Typedef struct _hash_db hash_db_t; What information about which hash tables need to be included in the structure? The core of a chained hash table is an array of type slist_head_t whose size is related to the number of packets. For general use, the number of packets should be determined by the user based on actual conditions. The array information of type slist_head_t consists of a pointer of type slist_head_t* pointing to the first address of the array and a size specifying the size of the array. The definition of the hash table structure type is as follows: Struct _hash_db{ Slist_head_t *p_head; // point to the first address of the array Unsigned int size; // number of array members In practical applications, the information can be any data type (void *), and secondly, the length of the record pointed to by the void * pointer needs to be known. For example, the length of the student record is sizeof(student_t), so the hash table structure is updated. The types are defined as follows: Struct _hash_db{ Slist_head_t *p_head; // point to the first address of the array Unsigned int size; // number of array members Unsigned int value_len; // the length of a record When storing or looking up a record, you can find the index value in the hash table by comparing it with a keyword (for example, student ID), and then add or find the record in the corresponding table item. When storing records, you need to provide keywords and records; when looking for records, you only need to provide keywords. Thus, keywords and records are two different concepts, and keywords have a special role, so keywords and records should be treated separately. For the student information management system, the keyword is the student number, the length is 6 bytes, and the record contains information such as name, gender, height, and weight. Therefore, in the definition of the student record structure, the keyword ID is separated. The student record is defined as follows: Typedef struct _student{ Char name[10]; // name Char sex; // sex Float height, weight; // height, weight Similarly, the length of the keyword is also determined by the user. When storing a record, the memory storage keyword needs to be allocated, so that the keyword is compared with the keyword used by the query when the query is read. Therefore, in the structure type of the hash table, it is necessary to include the keyword length information, and the definition of the update hash table structure type is as follows: Struct _hash_db { Slist_head_t *p_head; // point to the first address of the array Unsigned int size; // number of array members Unsigned int value_len; // the length of a record Unsigned int key_len; // the length of the keyword In particular, in the previous analysis, the most important concept of the hash table is the "hash function". The function of the hash function is to get the index of its corresponding record in the hash table by keyword (such as student ID). Values, the hash function should try to ensure that the records are evenly distributed among the various entries in the hash table. For different data, the user may choose a different hash function, so the hash function should be specified by the user. Based on this, a function pointer is added to the hash table structure to point to the user-defined hash function. The complete hash table structure type is defined as follows (hash_db.h): Typedef unsigned int (*hash_func_t) (const void *key); // Define the hash function type Struct _hash_db { Slist_head_t *p_head; // point to the first address of the array Unsigned int size; // array size Unsigned int value_len; // the length of a record Unsigned int key_len; // the length of the keyword Hash_func_t pfn_hash; // hash function Before using the various interface functions of the hash table , you first need to define a hash table instance with this type : Hash_db_t hash; If the system requires the use of more than one hash table, then only you need to use this type of instances to define a plurality of hash tables: Hash_db_t hash1; Voom Iris Mega Vape is so convenient, portable, and small volume, you just need to take them voom iris mega vape pen,voom iris mega vape disposable,voom iris mega vape device,voom iris mega vape box,voom iris mega vape travel kit Ningbo Autrends International Trade Co.,Ltd. , https://www.mosvapor.com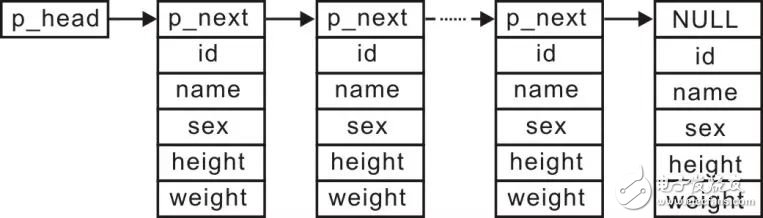

out of your pocket and take a puff, feel the cloud of smoke, and the fragrance of fruit surrounding you. It's so great.
We are the distributor of the Vapesoul & Voom vape brand, we sell vapesoul disposable vape,vapesoul vape bar, voom vape disposable, and so on.
We are also China's leading manufacturer and supplier of Disposable Vapes puff bars, disposable vape kit, e-cigarette
vape pens, and e-cigarette kit, and we specialize in disposable vapes, e-cigarette vape pens, e-cigarette kits, etc.